Deleted congressional tweets: the R code
tl;dr
Also see this R script examining deleted tweets.
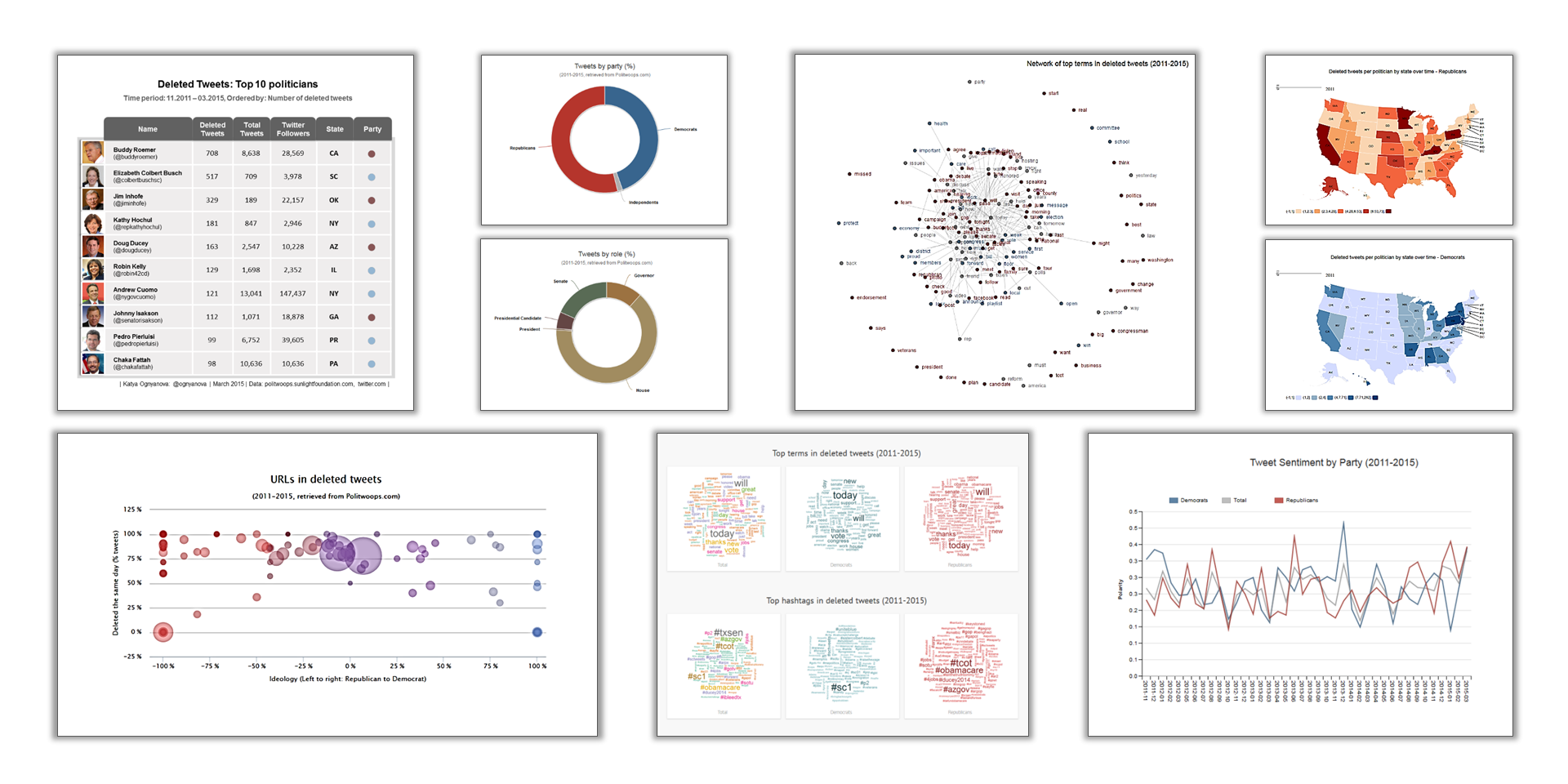
A few days ago I published a post containing interactive visualizations with the deleted tweets of US politicians. Those tweets were collected by the Politwoops project, maintained in the US by the Sunlight Foundation. I promised people to post the R code that grabs the tweet & politician data, cleans it, and generates the charts. As I started organizing the code, it seemed easy to take the next step and create a package that handles the data collection.
The PolitwoopsR package (now on GitHub) includes functions that extract tweet data from any most of the country-specific Politwoops projects. It also provides a way to scrape politician info, though that only works with the US project. I will be updating the package to make sure it works smoothly for all countries — but I should note that as of now I’ve only tested it with a few of those (US, UK, Argentina). You may still run into bugs with countries that have non-standard JSON format or URL form.
Additionally, I have posted an example script in this GitHub gist that collects and cleans this type of data. The current version of it includes the following steps:
- Getting the data using the PolitwoopsR package
- Expanding the short URLs in tweets and extracting domains
- Detecting the language of the tweets
- Cleaning the tweet text, stemming & stem completion, top terms
- Top hashtags by political party
- Tweet sentiment and polarity
- Collecting additional data from Twitter with the twitteR package
- Downloading the Twitter profile images of the politicians to use in visualizations
PolitwoopsR examples
Here are a few quick examples showing what the PolitwoopsR package can do at present.
Before getting started, you need to install PolitwoopsR from GitHub using the devtools package.
install.packages('devtools')
library(devtools)
install_github('kateto/PolitwoopsR')
library(PolitwoopsR)
Politwoops provides access to the tweet data in a paginated JSON (usually with 10 or 20 tweets per page). To get a data frame containing that data, you can use the function get_pw_tweets(). It takes four arguments: start.page (defaults to the first page), end.page (defaults to the last page available), domain (defaults to the US domain), and json.ext (defaults to “/index.json?page=”) which is where you find the json for the US and UK projects). Keep in mind that getting all the pages (over 750 for the US at present) may take some time.
# Get tweet JSONs - all pages from the US site: pw.df <- get_pw_tweets() # Get the first 5 pages only from the UK Politwoops tweets: pw.df <- get_pw_tweets(1, 5, "politwoops.co.uk") # Get the first 5 pages from Argentina's Politwoops tweets: tweet.df <- get_pw_tweets(1, 5, "www.politwoops.com/g/Argentina", ".json?page=")
The politician data is not available in a convenient format, but can still be scraped from HTML tables on the US site. To do that, use get_pw_pol(). As it only works with the US site, this function takes just two arguments – start.page (defaults to 1) and end.page (defaults to last).
# Get all politician data: pol.inf <- get_pw_pol()
The function merge_pw simply does a left outer join of the tweet and politician data frames, merging by twitter handle. That is to say: it adds columns to the tweet data frame (here pw.df) that contain information about the politician who authored each tweet.
# Combine tweet and politician data: pw.dfs <- merge_pw(pw.df, pol.inf)
A few of the additional helper functions in the package include short URL expansion and domain extraction in tweets:
# Expand URLs: pw.dfs$url.decoded <- url_expand(pw.df) # Extract domains from the URLs: pw.dfs$url.domain <- url_domain(pw.dfs$url.decoded)
[Update 15/04/02] The Dean Richards Bot Tale:
After putting together the PolitwoopsR package and posting it on GitHub, I sent out a tweet to let #rstats peeps know about it. The tweet was retweeted by Pew’s Claudia Deane (@c_deane), who was at the time getting a lot of unfortunate attention from an army of Russian bots.
I alerted Twitter to try and prevent further annoyance. Tough to say if this had any effect at all, plus the situation didn’t fit neatly in their standard “spam/harassment/copyright infringement” categories, especially as it involved multiple bot accounts rather than a single offender.
The story has no real conclusion, except to say that (as science fiction has taught us) robot armies are tough to beat. So if you landed here because of a Dean Richards bot tweet – well, hope you found this useful anyway. And please do say hi to our robotic overlords for me.